Data Lakehouse: Guia Completo para Entender e Aplicar na Prática


Quando falamos sobre transformação digital nas empresas, poucos conceitos têm chamado tanta atenção quanto o Data Lakehouse. E, de fato, não é fácil separar o que é tendência passageira do que realmente pode transformar a rotina dos negócios. Por isso, a proposta deste guia é ajudar você a entender, de forma clara (sem complicar), o que está por trás dessa arquitetura, como ela surgiu e como funciona na prática.
O objetivo aqui é sempre conectar teoria e prática, trazendo o que há de mais relevante sobre dados, sem rodeios. Então, prepare-se: vem uma conversa direta sobre como o Data Lakehouse pode (ou não) ser útil na trajetória de modernização das empresas.
Entendendo o que é, de fato, um Data Lakehouse
Sabe quando parece que cada área de TI tem uma definição diferente sobre o mesmo termo? Com Data Lakehouse não é diferente. Há quem veja como apenas uma evolução dos Data Lakes, enquanto outros enxergam uma revolução completa na forma de lidar com dados.
Mas, afinal, qual é a lógica?
Uma arquitetura que une dados e inteligência em um só lugar.
A IBM descreve a arquitetura Data Lakehouse como uma junção do melhor dos dois mundos: a flexibilidade dos Data Lakes (grande volume, todo tipo de dados) com o gerenciamento rigoroso e seguro dos Data Warehouses (transações, governança, desempenho). Ou seja, o grande trunfo do Data Lakehouse está em entregar performance e estrutura sem sacrificar a flexibilidade e o baixo custo. ([mais detalhes na IBM](https://www.ibm.com/br-pt/topics/data-lakehouse?utm_source=openai))
Na prática, é como se você pudesse reunir todos os dados da empresa (estruturados, semiestruturados e não estruturados) em um mesmo repositório, mantendo o controle rígido sobre quem pode acessar, atualizar e transformar essas informações. E, acima de tudo, garantir que os analistas de dados e cientistas possam trabalhar nesses dados sem lidar com uma arquitetura caótica.
Data Lake x Data Warehouse x Lakehouse: onde cada um faz sentido?
Antes de continuar, acho importante deixar claro como chegamos até aqui. Por muitos anos, o padrão dominante foi o Data Warehouse, focado em armazenar dados (bem) estruturados, capazes de responder a consultas rápidas e específicas, normalmente para reportes e BI clássico. Data Lakes surgiram como alternativa para armazenar grandes quantidades de dados, em diferentes formatos e sem uma estrutura rígida. O problema? Com o tempo, muita empresa virou refém do data swamp — aquele pântano de dados impossível de navegar e entender.
O Data Lakehouse aparece, então, para atacar esse ponto. Ele pega a flexibilidade dos Data Lakes (que tanto atrai quem trabalha com machine learning, big data e analytics avançados), e combina com os mecanismos de controle, governança e desempenho dos Warehouses.
Como a arquitetura Lakehouse funciona – e o que muda na prática
Vamos separar em partes? Assim fica mais fácil entender como tudo se encaixa.
- Armazenamento de dados em formatos abertos: Uma das grandes sacadas do Lakehouse está em usar formatos de armazenamento aberto, como Parquet, ORC e Avro. Isso permite que diferentes ferramentas (e empresas) consigam acessar e trabalhar nesses dados com facilidade.
- Transações ACID: A base desses sistemas é garantir segurança nas operações. As propriedades ACID (Atomicidade, Consistência, Isolamento, Durabilidade) são pilares conhecidos do mundo relacional e agora se aplicam também ao Lakehouse, permitindo atualizações sem medo de corromper tabelas ou perder informações.
- Camada de metadata: É aqui que começa a “magia”. Toda ação no Lakehouse é registrada. Sabemos quem fez, quando, o que mudou, qual esquema foi utilizado e como os dados estão organizados. Isso viabiliza governança, auditoria e qualidade.
- Motores de consulta otimizados: O Lakehouse suporta múltiplos tipos de consulta, sejam SQL tradicionais, workloads de Data Science, dashboards em tempo real. Assim, você tem o desempenho de um Warehouse com a elasticidade de um Lake.
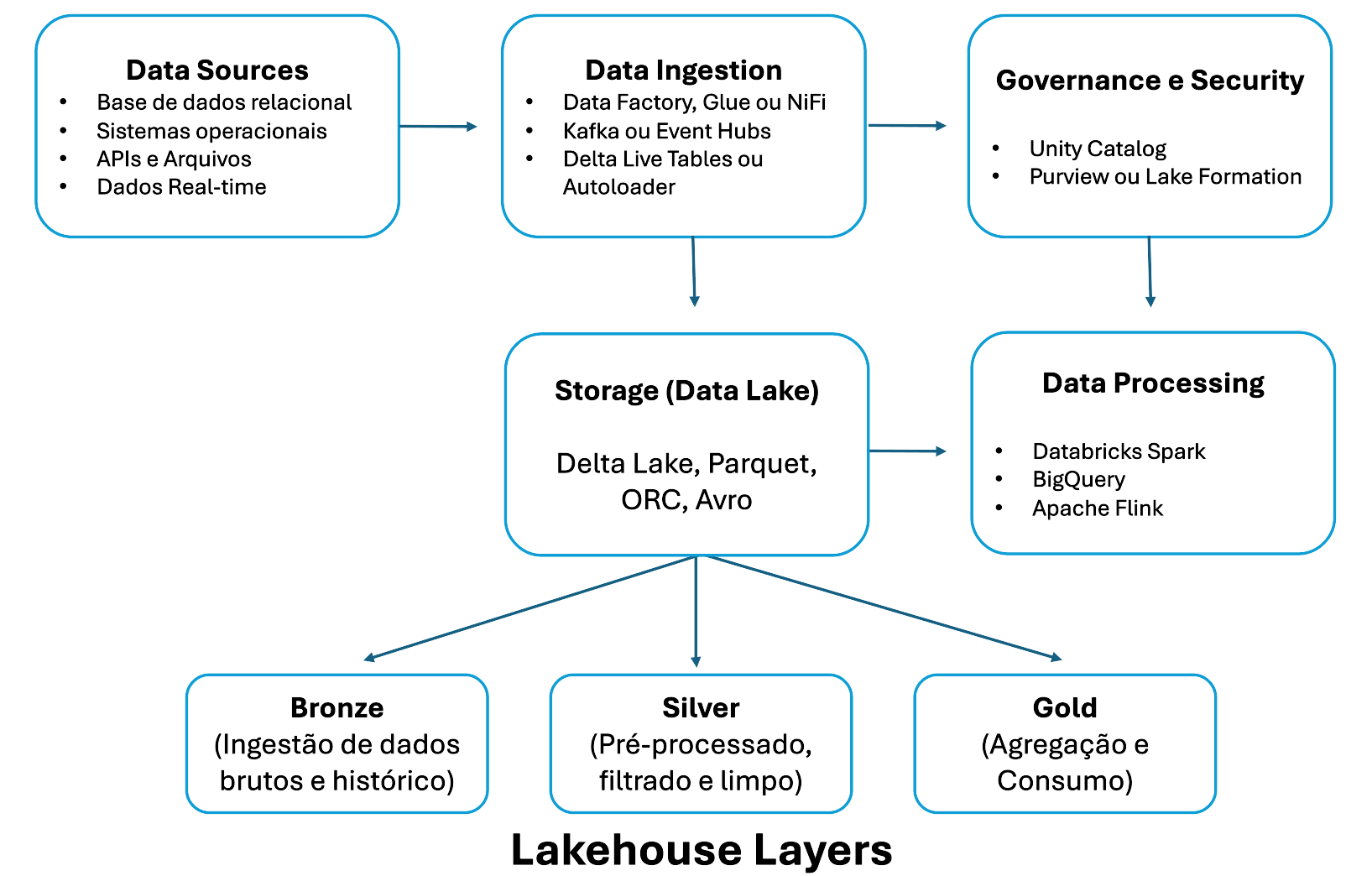
Esses pontos formam o “core” da arquitetura Lakehouse. Quando olhamos para ferramentas e tecnologias existentes, é fácil identificar padrões: Delta Lake, Apache Iceberg e Unity Catalog são algumas das soluções que vestem esse conceito, cada uma com suas peculiaridades.
A importância das transações ACID para integridade dos dados
Talvez você não lembre do que significa cada letra do ACID, mas certamente já reclamou quando uma tabela ficou inconsistente, mesmo sem querer. No Lakehouse, as transações ACID evitam muitos desses problemas. Elas garantem que, mesmo em ambientes massivos (e muitas vezes caóticos) de big data, as alterações sejam seguras.
- Atomicidade: Ou tudo é feito, ou nada é feito.
- Consistência: O resultado final garante as regras estabelecidas.
- Isolamento: Processos concorrentes não se atropelam.
- Durabilidade: Não perdemos o que já estava persistido, mesmo se houver uma falha.
Parece simples, porém, faz toda diferença. Em contextos onde machine learning depende de dados atuais e confiáveis, falhas nesse processo podem comprometer projetos inteiros. E, honestamente, não é raro ver dados “estranhos” ou “falta de dados” em pipelines que ignoram essas práticas.
Transações ACID mudam o jogo na governança de dados.
A força dos formatos abertos: flexibilidade e interoperabilidade
Outro ponto central no Lakehouse é a escolha por formatos abertos. Isso pode parecer detalhe técnico, mas muda tudo.
Se você já tentou migrar dados entre sistemas proprietários, sabe o drama que pode ser. Muitas vezes, temos que passar por processos demorados, erros esquisitos e retrabalho. Com a adoção de Parquet, ORC ou Avro, o cenário melhora muito.
Esses formatos permitem:
- Trabalhar com arquivos massivos, sem sacrificar performance.
- Fazer queries com múltiplas ferramentas: Spark, Presto, SQL Engines e muitos outros serviços.
- Garantir compressão eficiente (armazenamento mais barato).
- Facilitar auditorias, controle de versão e schema evolution (mudança de formato ao longo do tempo).
 Em resumo, a escolha dos formatos abertos é o que permite que empresas tenham liberdade para evoluir sua stack, evitando o famoso “lock-in” tecnológico. Decisão que assume papel central em ambientes onde mudanças rápidas fazem parte do dia a dia.
Em resumo, a escolha dos formatos abertos é o que permite que empresas tenham liberdade para evoluir sua stack, evitando o famoso “lock-in” tecnológico. Decisão que assume papel central em ambientes onde mudanças rápidas fazem parte do dia a dia.
Governança de dados: evitando o data swamp e promovendo qualidade
Imagine um enorme oceano de dados, sem controle, sem requisitos de segurança e, pior, sem saber “quem mexeu no quê”. O data swamp é esse cenário caótico, e o Lakehouse trouxe mecanismos para combater essa bagunça.
Governança não precisa (e não deveria) ser assustador. O segredo é aplicar controles inteligentes, sem atrapalhar quem precisa criar soluções rápidas. Algumas práticas essenciais incluem:
- Gestão de metadados detalhada: informações de proveniência, versionamento e histórico de alterações.
- Catálogos de dados: estruturas como o Unity Catalog oferecem um índice simples (mas poderoso) de onde está cada dado, quem pode acessar e como estão sendo usados.
- Políticas de acesso refinadas: não é porque o dado está lá, que todo mundo pode tudo. Permissões precisam ser granulares, ajustadas ao perfil de cada usuário.
- Auditoria e rastreabilidade: logs detalhados apontam qualquer ação incoerente, reforçando segurança e cumprimento de normas.
Governança não é obstáculo. É ponte para confiança e consistência.
As camadas da arquitetura Lakehouse
Uma das características marcantes desse modelo é a definição clara de camadas. Isso contribui para modularidade, escalabilidade e agilidade no uso.
Camada de armazenamento
Onde os dados vivem. Geralmente em formatos abertos e sobre storage (quase sempre em nuvem). O ponto forte aqui é a elasticidade e o baixo custo.
Camada de metadados
O celeiro das informações sobre cada dado. Etapas de ingestão, esquemas, evolução ao longo do tempo, logs de transações. É nesta camada que a governança e o rastreio ganham vida.
Camada de processamento e motores de consulta
Engloba tudo que manipula e consulta os dados: desde um simples SELECT até algoritmos avançados de machine learning. Spark, Trino, Flink e serviços SQL trabalham juntos, extraindo o valor real dos dados.
 Cada camada tem um papel, e juntas formam a estrutura que faz o conceito Lakehouse funcionar de verdade, indo muito além do discurso.
Cada camada tem um papel, e juntas formam a estrutura que faz o conceito Lakehouse funcionar de verdade, indo muito além do discurso.
Aplicações práticas do Lakehouse: machine learning, BI e workloads diversos
Talvez a principal razão para o crescimento do Lakehouse esteja na amplitude de aplicações práticas. E, para falar a verdade, esse é um dos pontos que mais aparecem nas empresas que buscam resultados reais.
- Permite análise de dados estruturados (tabelas, números financeiros, relatórios operacionais).
- Suporta ingestão e trabalho em dados semiestruturados ou não estruturados (logs, fotos, textos livres, áudios).
- Facilita a construção de modelos de machine learning: os times de ciência de dados podem acessar dados limpos, governados e versionados com facilidade, acelerando o ciclo de experimentos e deploy.
- Distribui workloads de BI, dashboards em tempo real, análise preditiva e uso em aplicações de IoT.
 Segundo a DataCamp, a arquitetura Lakehouse simplifica bastante o processo de criação, treino e deployment de modelos, o que reduz custos e obstáculos práticos em projetos de IA. Você pode acessar, preparar e transformar grandes volumes de informação sem precisar migrar tudo para racks separados, como ocorria nos antigos warehouses.
Segundo a DataCamp, a arquitetura Lakehouse simplifica bastante o processo de criação, treino e deployment de modelos, o que reduz custos e obstáculos práticos em projetos de IA. Você pode acessar, preparar e transformar grandes volumes de informação sem precisar migrar tudo para racks separados, como ocorria nos antigos warehouses.
Essa convergência de usos é o que apareceu de forma muito clara nos estudos da Databricks. Desde o BI tradicional até iniciativas mais corajosas de machine learning ou mesmo IA generativa, o Lakehouse oferece um ambiente apto a responder a diferentes demandas.
Tecnologias atuais: Delta Lake, Apache Iceberg, Unity Catalog
Quando o tema é modernização da stack de dados, surgem nomes técnicos que, para muitos times, parecem sinônimos, mas trazem nuances importantes. Você provavelmente já ouviu falar em Delta Lake, Apache Iceberg e Unity Catalog, certo?
- Delta Lake: solução bastante adotada que implementa as ideias centrais do Lakehouse, trabalhando sobre storage em nuvem (Azure Data Lake, Amazon S3, etc.), aplicando logs de transações ACID, controle de versionamento e schemas flexíveis.
- Apache Iceberg: também trabalha sobre storage aberto, mas traz foco em performance para conjuntos massivos, com gerenciamento aprimorado de snapshots, aceleração de consultas e evolução transparente de schemas.
- Unity Catalog: camada adicional de governança. Um catálogo centralizado de metadados e permissões, com políticas refinadas de controle e rastreabilidade — ponto cada vez mais cobrado em contextos de compliance, LGPD e companhia.
Essas tecnologias mostram como o Lakehouse deixou de ser conceito e virou prática acessível. Com interfaces cada vez mais intuitivas e documentações fartas, hoje é possível montar pipelines e produtos de dados completos aproveitando essas soluções.
Evolução: como chegamos a esse modelo?
Muita gente pensa que o Lakehouse surgiu da noite para o dia. Na verdade, foi resultado de uma longa sequência de aprendizados (e tropeços). Ao tentar resolver os problemas dos Data Lakes (falta de governança, performance inconsistente, dificuldade de integração), comunidades de engenheiros criaram camadas intermediárias, catálogos, engines smart e formatos otimizados. “Empilhar” soluções, claro, não era sustentável. Foi aí que a ideia de um modelo unificado, aberto e controlado ganhou força.
A jornada do Lakehouse é feita de tentativas, acertos e evolução constante.
Referências como a plataforma de inteligência de dados detalham como o Lakehouse nasceu da prática e da necessidade. Não foi puro acaso — é tecnologia que pegou porque resolveu gargalos bem reais.
Vantagens e ganhos para empresas
Agora talvez você se pergunte: será mesmo que faz sentido investir nisso? A resposta, claro, depende do contexto. Mas algumas vantagens são recorrentes, e aparecem em projetos variados:
- Redução de custos: manter grandes volumes de dados em sistemas tradicionais de Data Warehouse é oneroso. O Lakehouse, ao rodar sobre camadas de storage baratas, traz economia instantânea.
- Agilidade operacional: experimentos, consultas e deployments de novas soluções são mais rápidos.
- Escalabilidade real: cresça (ou diminua) sua plataforma sem precisar redesenhar tudo do zero. O modelo Lakehouse foi pensado para lidar com expansão em diferentes níveis.
- Suporte a cargas mistas: analytics tradicional e workloads modernos (IA, ML, streaming), em um só ambiente, evita retrabalho e impede silos de dados.
- Flexibilidade: com formatos abertos e catálogos unificados, atualizar ou migrar segmentos da stack virou tarefa viável e menos traumática.
 É por esses motivos que empresas modernas que buscam alinhar inovação, controle de dados e eficiência de investimento têm adotado o Lakehouse como padrão, movimento detalhado em iniciativas recentes. Tenho visto um salto significativo em projetos que apostam nesse modelo para integrar dados de setores como finanças, RH, vendas e operações em um só “guarda-chuva”.
É por esses motivos que empresas modernas que buscam alinhar inovação, controle de dados e eficiência de investimento têm adotado o Lakehouse como padrão, movimento detalhado em iniciativas recentes. Tenho visto um salto significativo em projetos que apostam nesse modelo para integrar dados de setores como finanças, RH, vendas e operações em um só “guarda-chuva”.
Como começar? Sugestões práticas de implementação
Cada cenário demanda um ritmo — não existe receita universal. Porém, há alguns passos que podem servir de bússola para quem está considerando a adoção desse modelo:
- Desenhe o mapa atual de dados: entenda o ambiente, origem, como são acessados e quem precisa deles.
- Defina prioridades: nem tudo precisa migrar de uma vez. Comece por projetos estratégicos (Analytics, BI, experimentação com IA).
- Adote formatos abertos: troque arquivos proprietários por Parquet, ORC, Avro. Isso já abre portas para novas ferramentas.
- Implemente controle de metadados: Catálogo, versionamento, logs de transações. Não pule esta etapa.
- Engaje as áreas de negócio: a arquitetura Lakehouse só gera valor real se for usada por quem traz demandas concretas.
Nem sempre o caminho será linear. Vão surgir dúvidas técnicas, dilemas de custo, ajustes de performance e… talvez um pouco de resistência. Tudo bem, faz parte do processo — ninguém disse que unificar o mundo dos dados seria tarefa fácil. Mas, com clareza conceitual e objetivos bem definidos, os ganhos logo aparecem.
Conclusão
Construir uma arquitetura moderna de dados é mais do que seguir modismos. É, sobretudo, permitir que informação circule de maneira controlada, transparente e útil para o negócio. O Data Lakehouse nasceu da necessidade e evoluiu porque resolve desafios concretos: entregar performance sem amarras, garantir governança sem sufocar inovação e permitir integração real entre times de tecnologia e áreas de negócio.
Eu sigo acompanhando de perto como essa arquitetura tem mudado rotinas e estratégias de empresas de todos os portes. Se você busca insights práticos, quer trocar experiências ou entender se o Lakehouse faz sentido para seu cenário, siga acompanhando o Blog e conecte-se comigo. Falando de dados, a inovação é contínua — mas a conversa nunca termina.
Sobre o Autor

0 Comentários