Introdução à modelagem de dados: relacional vs dimensional


Quando pensamos em dados, a ideia talvez remeta a planilhas, tabelas ou bancos complexos que parecem distantes da vida cotidiana. Mas a verdade é que organizar a informação vai muito além disso, trata-se de criar sistemas compreensíveis para que os dados realmente possam servir como base para decisões acertadas. Este artigo é um passeio prático pelas diferenças entre a modelagem relacional e dimensional, incluindo dicas para construir, adaptar e governar modelos de dados que realmente funcionem.
Modelagem de dados, afinal, o que é?
Modelar dados é criar representações visuais, lógicas e físicas de como informações se relacionam. Segundo a definição clássica, esse processo passa por três etapas:
- Modelagem conceitual: Identifica entidades principais, seus atributos e os relacionamentos entre elas.
- Modelagem lógica: Estrutura dados em tabelas (ou outro formato, dependendo do contexto), define chaves e ligações de dependência.
- Modelagem física: Aplica a estrutura na plataforma de banco de dados, considerando índices, performance e armazenamento.
Construir modelos de dados é transformar perguntas em respostas organizadas.
Essas etapas aparecem seja para um pequeno controle de estoque em Excel ou num projeto de Data Lakehouse complexo no Azure.
Modelagem relacional: estrutura ordenada para o dia a dia
Criada na década de 1970 por Edgar Codd, a modelagem relacional é aquela arquitetura de base que, até hoje, sustenta bancos de dados transacionais e a imensa maioria dos sistemas que processam operações do cotidiano corporativo.
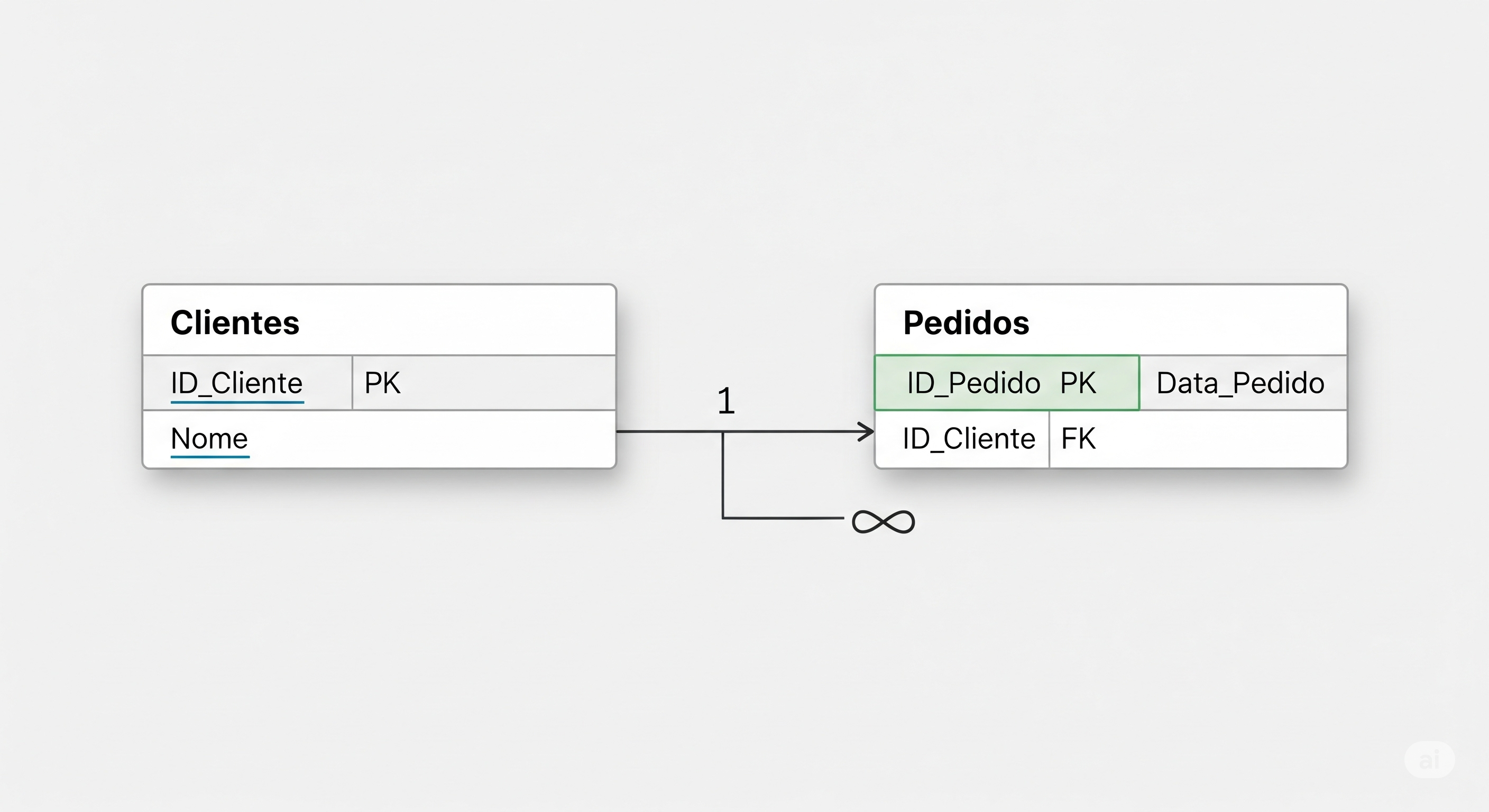
Como funciona na prática?
Imagine um sistema de vendas: há uma tabela para Clientes e outra para Pedidos. Cada cliente pode ter vários pedidos, mas cada pedido está atrelado a um cliente só. No mundo relacional, isso é feito com chaves primárias e estrangeiras que criam integrações lógicas. Assim:
- Chave primária (PK): Identifica cada registro de uma tabela de modo único.
- Chave estrangeira (FK): Relaciona diferentes tabelas entre si, apontando para a chave primária de outra tabela.
Essa organização permite que as atualizações mantenham integridade. Se excluo um cliente, qual o impacto nos pedidos? Um bom modelo relacional impede sobrevivência de dados “órfãos”. Isso atende bem transações que não podem falhar, por exemplo processar um pagamento ou dar baixa em estoque. Por isso, o modelo relacional está em tantas soluções de bancos de dados até hoje.
Vantagens e limitações do modelo relacional
Por trás dessa ordem aparente existem pontos positivos e desafios:
- Forte integridade e consistência (modelo ACID).
- Facilidade de consulta para operações padrão.
- Limite de escalabilidade horizontal em grandes volumes (conforme a própria documentação Azure).
- Normalização rigorosa às vezes complica agregações requeridas por relatórios gerenciais.
Vale admitir: para o BI tradicional, o modelo relacional pode ser um pouco burocrático. Mas, para sistemas OLTP, ele é praticamente imbatível.
Modelagem dimensional: perguntas rápidas, respostas diretas
A modelagem dimensional aparece quando relatórios se tornam o centro das atenções. E BI precisa mesmo de agilidade. Kimball defendia que esta abordagem, ao contrário da entidade-relacionamento tradicional, entrega performance mesmo em bases enormes para análise.
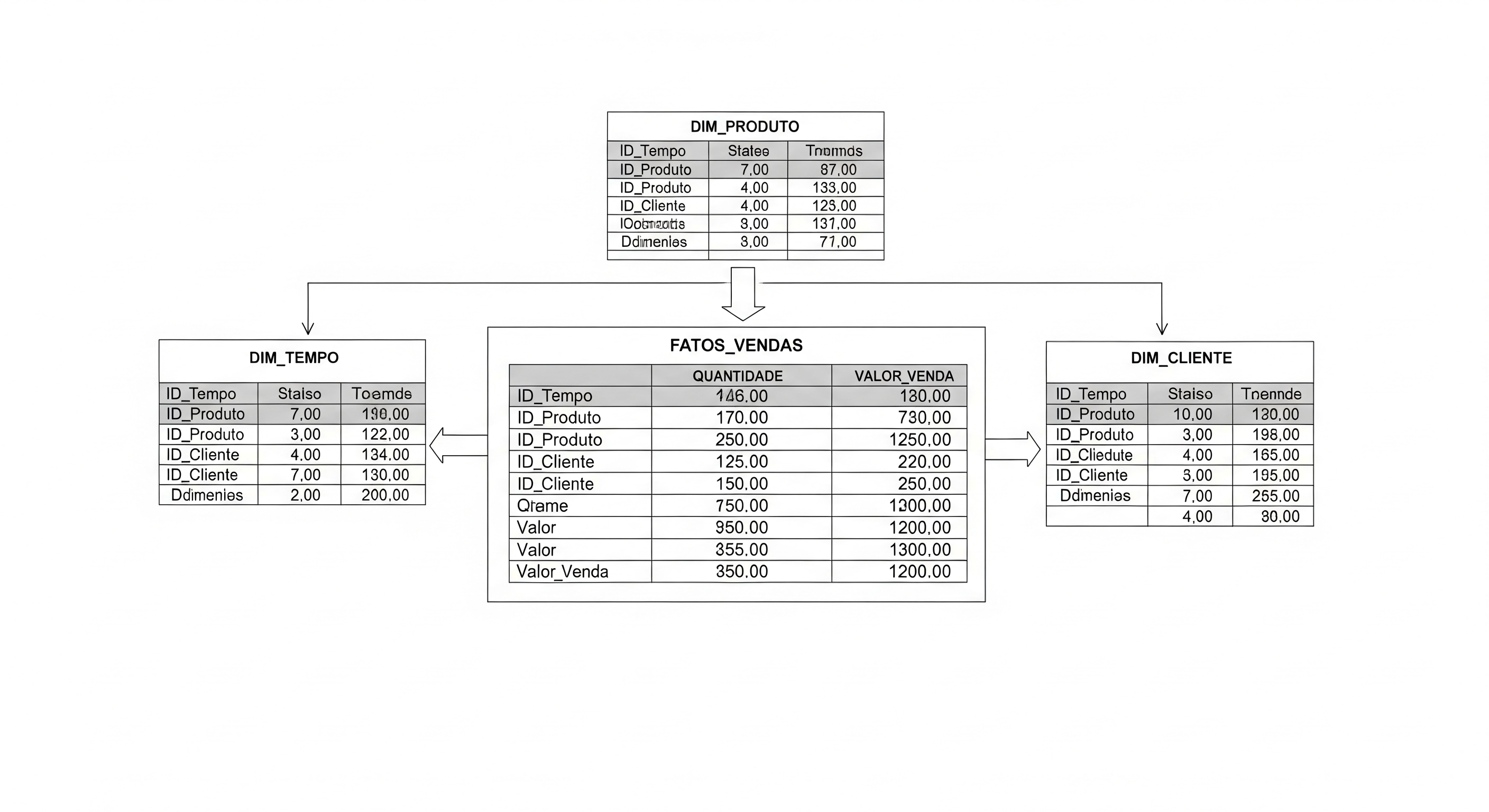
No modelo dimensional, os dados se organizam em tabelas fato (onde ficam as transações ou métricas) e dimensões (categorizações como cliente, tempo, produto).
Esquema estrela e floco de neve
Dois desenhos clássicos aparecem aqui:
- Esquema estrela: Todas as dimensões conectam-se diretamente à tabela fato, tornando a compreensão mais intuitiva.
- Esquema floco de neve: As dimensões são “normalizadas”, ou seja, quebradas em tabelas auxiliares. O modelo ganha granularidade, mas fica mais complexo para quem vai construir painéis de BI.
Dimensional é para responder perguntas, relacional é para registrar fatos.
Nesse tipo de modelagem, é natural haver certa redundância nos dados das dimensões. Diferente do que acontece no relacional, aqui o objetivo é acelerar cálculos. O objetivo é criar um repositório de dados consultado intensamente, como acontece nos data warehouses modernos.
Onde isso aparece no dia a dia?
Os modelos dimensionais estão nos bastidores de dashboards de vendas, indicadores de desempenho, análise de lucratividade e em quase qualquer solução de BI que extraia dados de fontes transacionais para gerar insights.
Ferramentas como Power BI, Tableau, Power Pivot no Excel e soluções de data warehouse na nuvem seguem o paradigma dimensional. E em ambientes Azure, estruturar o modelo dimensional permite criar pipelines e visualizações otimizadas mesmo em cenários de alto volume de dados ou múltiplas fontes (como ocorre em projetos usando formatos Parquet e ORC).
Etapas práticas da modelagem: do papel ao SQL
Planejamento conceitual
No início, precisamos entender o negócio e listar os principais elementos a serem monitorados. Se for uma loja, por exemplo: Produtos, Vendas, Clientes, Categoria de Produto.
Nessa fase, desenhamos diagramas. O foco é capturar relacionamentos, especializações (um produto pode ser físico ou digital?) e atributos básicos.
Modelagem lógica
Transformamos os conceitos em algo mais técnico. Aqui, cada entidade vira uma tabela, cada atributo uma coluna. Começamos a discutir:
- Quais são os identificadores únicos? (chaves primárias)
- Onde existem vínculos entre tabelas? (chaves estrangeiras)
- O que diferencia as dimensões dos fatos nos modelos de BI?
Por exemplo: a tabela “Vendas” pode ter uma coluna ID_Venda como PK e ID_Cliente como FK.
Modelagem física
É o momento de colocar a mão na massa. Os diagramas viram comandos SQL ou definições em ferramentas cloud. Aqui, escolhem-se tipos de dados, índices, configurações de performance e até formatos de arquivo (CSV, Parquet, etc). E, sim, é possível montar boas estruturas até com recursos como Microsoft Excel e Power Pivot para pequenos projetos.
 Conceitos-chave: chaves, fatos, dimensões e integridade
Conceitos-chave: chaves, fatos, dimensões e integridade
Para um modelo funcionar, certos conceitos aparecem o tempo todo:
- Chave primária (PK): Valor que identifica um registro. Deve ser único, não pode mudar.
- Chave estrangeira (FK): Liga tabelas; um campo na tabela A faz referência à PK na tabela B.
- Tabela fato: Onde ficam os eventos, como vendas, transações financeiras, registros de acesso.
- Tabela dimensão: Descreve os detalhes, como nome do produto, categoria, região, datas.
Redundância pode atrapalhar? No modelo relacional, sim. Por isso, se investe tanto em normalização, ou seja, dividir os dados entre tabelas para evitar repetição.
Já no dimensional, aceita-se alguma redundância para agilizar consultas. Cuida-se, entretanto, para evitar divergências nas dimensões (exemplo: um nome de cliente diferente em tabelas distintas).
Cases típicos: onde cada abordagem se encaixa?
Às vezes, a escolha pelo modelo depende mesmo do objetivo:
- Sistemas transacionais (OLTP): Rotinas bancárias, ERP, e-commerce utilizam modelo relacional, pois precisam garantir atualização contínua e dados sempre íntegros.
- BI e Data Warehouse: Quando relatórios multidimensionais são necessários, e queries complexas precisam de rapidez, a modelagem dimensional aparece como melhor opção.
O segredo está em alinhar o modelo com o objetivo do projeto.
Ferramentas e Recursos para Modelagem de Dados
Não é preciso ser DBA para começar. Hoje, existem diversas ferramentas no mercado que atendem a diferentes necessidades de modelagem de dados, tanto gratuitas quanto pagas:
- Excel e Power Pivot: Excel, com suas funcionalidades básicas, e Power Pivot, que permite análises mais avançadas, são ótimas opções para criar modelos dimensionais e relacionais em pequenos projetos, além de possibilitar a construção de dashboards interativos.
- DrawSQL: Uma ferramenta online para criar e visualizar diagramas de esquemas de banco de dados, especialmente projetada para equipes de desenvolvimento. Ele permite que você modele visualmente bancos de dados relacionais, colabore com outros membros da equipe em tempo real e gere automaticamente scripts SQL para criar ou modificar seus bancos de dados.
- MySQL Workbench: Uma ferramenta gratuita que ajuda a modelar, desenvolver e administrar bancos de dados MySQL. Possui recursos para criar diagramas e gerenciar a estrutura de dados de forma intuitiva.
- BR Modelo Web: Uma ferramenta online e de código aberto para modelagem de bancos de dados, focada em modelagem entidade-relacionamento, especialmente para o ensino e aprendizado dessa área. É uma versão web do projeto brModelo, que surgiu como ferramenta de apoio ao ensino de projeto de bancos de dados relacionais. A ferramenta permite criar diagramas conceituais, lógicos e físicos de bancos de dados, além de converter entre esses diferentes níveis de modelagem, e ainda oferece funcionalidades como visualização de relacionamentos e templates para auxiliar no desenvolvimento.
Até mesmo soluções open source, como o pgModeler, uma ferramenta de modelagem para PostgreSQL, podem ganhar vida com uma boa modelagem inicial. Vale sempre ressaltar que, independentemente da ferramenta, os fundamentos seguem os mesmos.
Boas práticas para evolução e governança
À medida que os negócios mudam, seu modelo também precisa evoluir. Algumas boas práticas ajudam a evitar dores de cabeça:
- Evite colunas genéricas demais (tipo “dados extras”). Defina bem atributos e explique propósitos.
- Mantenha a documentação em dia. Isso vai poupar perguntas e acelerar integrações.
- Desenhe para mudanças. Modelos flexíveis suportam evolução do negócio sem refazer tudo do zero.
- Verifique sempre a integridade. Ferramentas de automação ajudam a identificar inconsistências cedo.
- Engaje times de negócio e TI. Modelagem não é tarefa só de técnicos; quem usa a informação deve participar das definições.
Um modelo vivo acompanha o crescimento do negócio.
Governança começa pelo desenho claro: quem pode inserir, alterar, excluir ou consumir dados? No ambiente Azure, políticas de segurança e automação apoiam tanto o controle quanto a escalabilidade dessas estruturas.
Conclusão
A arte de modelar dados não precisa ser um mistério. Entender a diferença entre organizar informações para processar transações (modelo relacional) e para impulsionar as análises (modelo dimensional) faz toda a diferença na rotina. Entre tabelas, chaves, fatos e dimensões, existe uma ponte decisiva para quem deseja projetos de dados confiáveis e insights realmente úteis.
No final, talvez a melhor abordagem seja combinar: usar a robustez do modelo relacional onde a atualização e integridade são indispensáveis, e desenhar estruturas dimensionais para acelerar respostas em ambientes de BI.
Artigos Relacionados



Sobre o Autor

0 Comentários